Explore the power of running private, customizable, and offline AI models on your hardware.
Introduction
Large Language Models (LLMs) have transformed how we interact with AI, offering capabilities like text generation, summarization, and chat interfaces. While many use cloud-based solutions, running Large Language Models locally has several advantages:
- Privacy: Keep your data secure with no cloud dependency.
- Customization: Fine-tune models for personal tasks.
- Offline Access: Use AI without an internet connection.
In My #ALX_AI Project 9, I explored tools like Ollama and LM Studio to set up and run these models on my computer.
Why Run LLMs Locally?
Here’s why you should consider running LLMs locally:
- Data Control: No third-party servers—your data stays on your device.
- Flexibility: Customize models to suit your needs.
- Performance: Offline AI ensures faster response times for specific tasks.
However, there are challenges:
- Hardware Limitations: Larger models may require high-performance machines.
- Setup Complexity: Installation and optimization can be technical.
Tools and Process
1. Ollama
- A lightweight runner for LLMs on all major platforms.
- Installation: Simple one-line commands for Linux or downloadable installers for Windows/Mac.
- Model Used: Mistral 7B for chat and text generation.
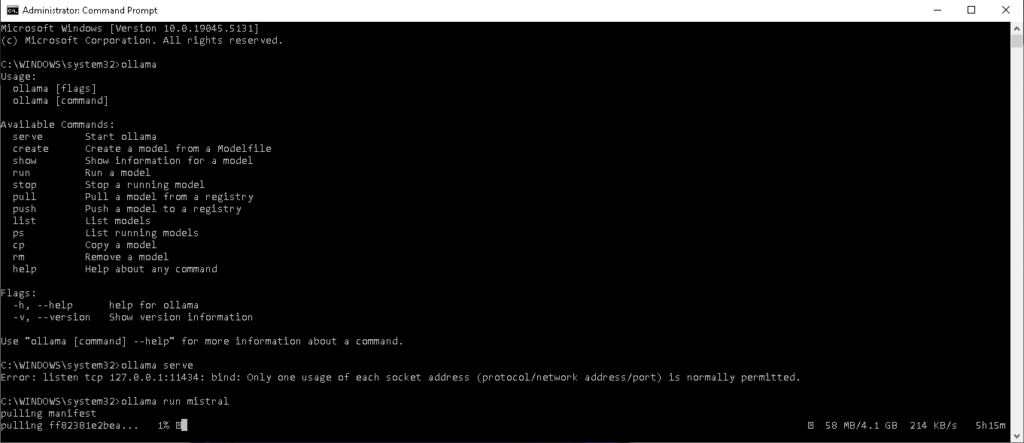
- Commands:
- To check that ollama is correctly installed, open the terminal and type
ollamathis will list available commands. You can also visithttp://127.0.0.1:11434/to check if ollama is running. - To run ollama:
ollama serve - To run the model:
ollama run mistral. - To quit:
/bye.
- To check that ollama is correctly installed, open the terminal and type
2. LM Studio
- User-friendly software to download and run LLMs.
- Features include model management and an interactive chat interface.

- Setup:
- Download models directly or manually place them in the required directory.
- Select a model to start chatting!
Outcomes and Insights
- Run the Mistral 7B model locally using both tools.
- Observe trade-offs between model size and performance:
- Smaller models are faster but may “hallucinate” more.
- Larger models offer better accuracy but require more resources.
Conclusion
Running LLMs locally empowers users with privacy, flexibility, and independence from internet connectivity. Tools like Ollama and LM Studio simplify this process, making it accessible for tech enthusiasts and professionals alike.
Interested in trying this? Check out these resources:
Related article: LLMs as Creative Partners: Your Guide to Local AI Exploration